The most common reason people give up on tracking their bloodwork is that the data is locked inside PDFs no one wants to retype. Every lab uses a different layout, the units shift between US and SI conventions, and a single panel can scatter the same biomarker name across three pages. Health3 was built to solve that problem first, so everything downstream of it became possible.
This is the story of how we built it: the architecture decisions, the tradeoffs we navigated, and what shipping a health-data app to a global user base actually involved.
The Problem With Existing Lab-Result Apps
The patient-facing health apps we tested fell into two camps. Either they required the user to retype every value by hand, guaranteeing nobody would stick with it, or they only worked with two or three specific lab providers, leaving everyone else outside.
We started Health3 with one rule: import the PDF the user already has. Whatever the layout, whatever the units, whatever the language. That single decision shaped every technical choice that followed.
Core Features at a Glance
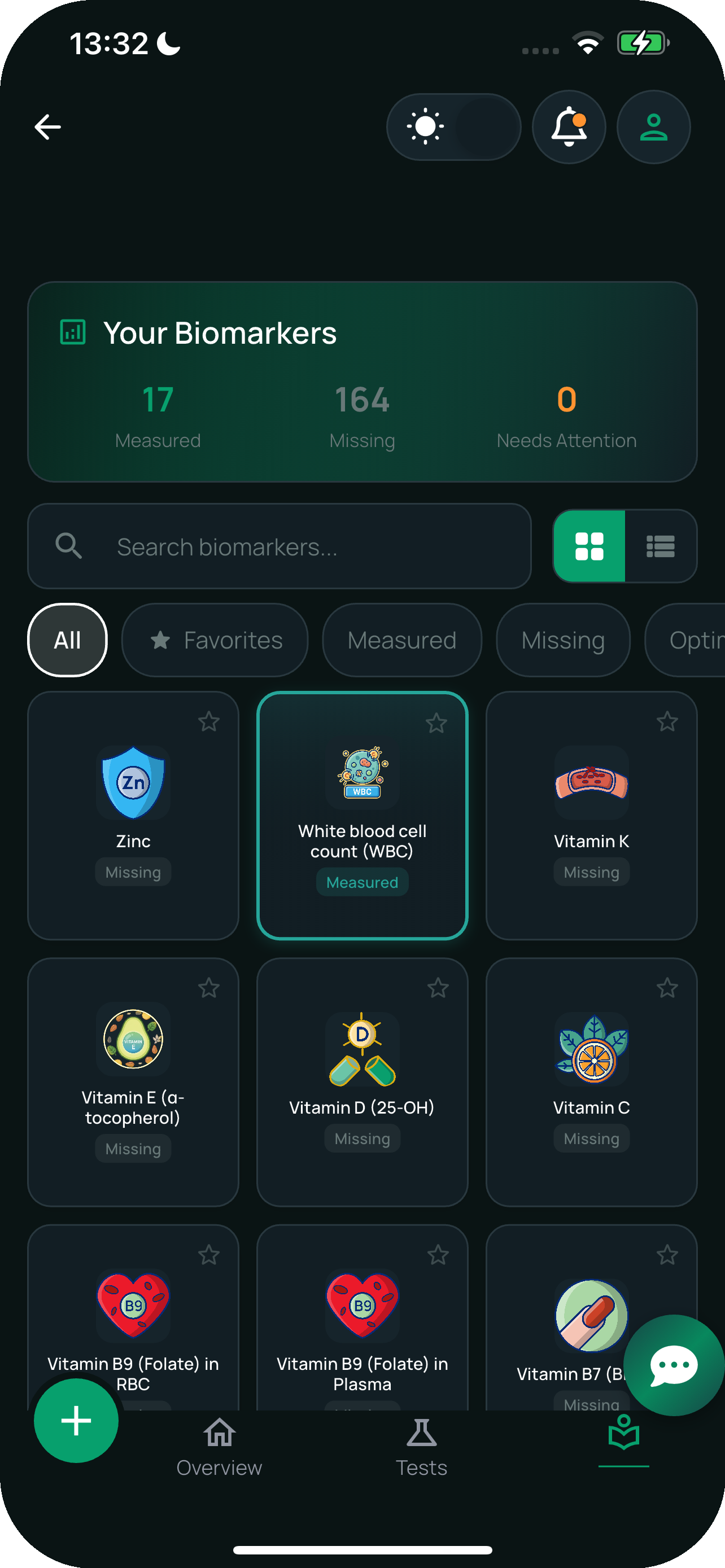
- PDF lab-report import: drop in a multi-page report, get back structured per-biomarker values with units normalised
- Biomarker library with hundreds of biomarkers, plain-language explanations, normal ranges, and trend context
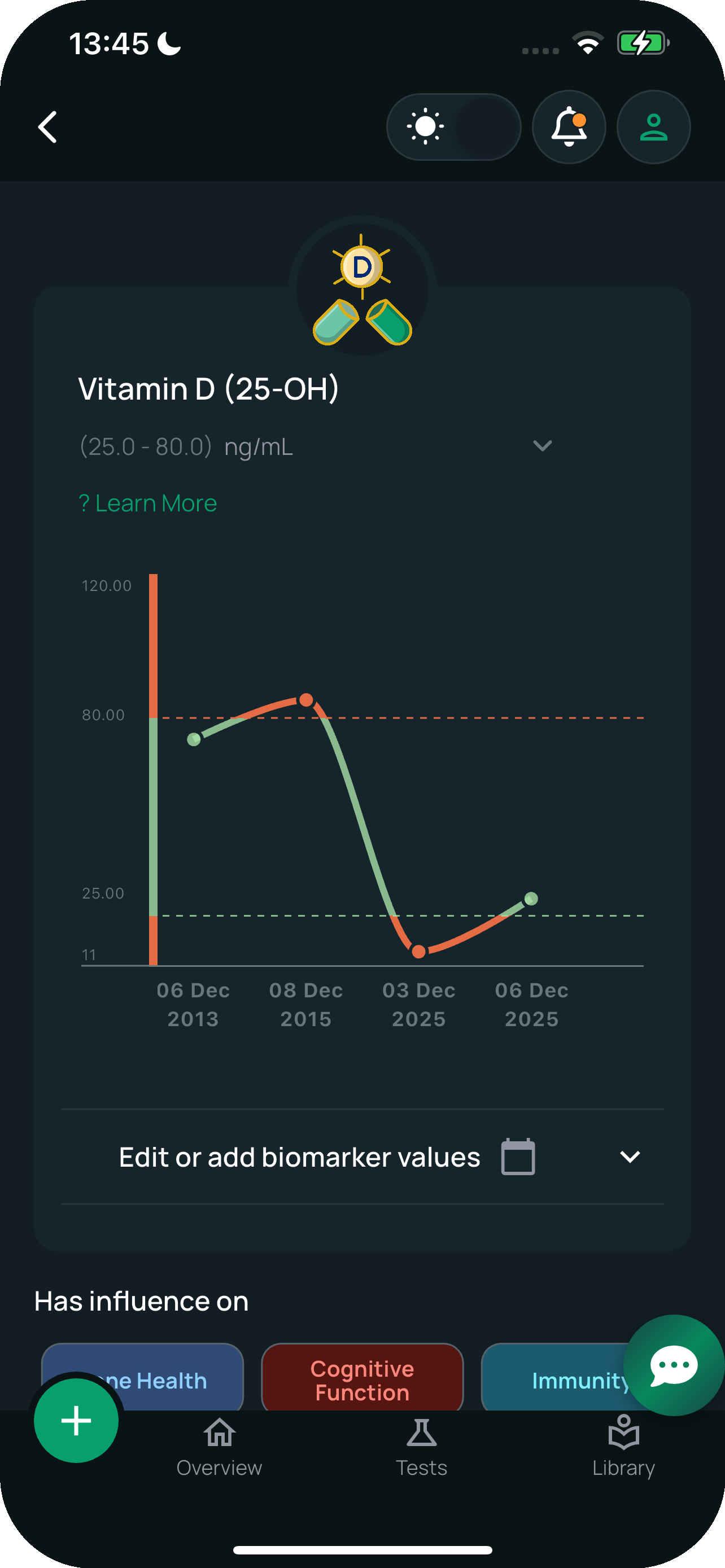
- Time-series tracking so every imported result feeds into the same per-biomarker chart, and trends emerge across years
- Unit conversion at runtime: mg/dL ↔ mmol/L (and the equivalents for every other panel) handled per biomarker, not globally
- 27+ countries of organic users without paid acquisition
- Privacy-first architecture: labs uploaded to S3 are scoped to the user, deleted after processing, never used as training data
- HealthKit and Google Fit sync for body composition and lab inputs
- Topic-level deep dives: biomarker clusters explained in context (lipid panel → cardiovascular framing, glucose + HbA1c → metabolic framing)
Why Flutter Was the Pragmatic Choice for Health-Data UX
Health3 is the kind of app where the visual quality of a chart matters as much as the data behind it. Users decide whether to trust a health app in the first three seconds they see it. We chose Flutter for two reasons: native-quality rendering on both platforms, and the ability to ship the same chart code on iOS, Android, and (eventually) web.
The renderer compiles to native ARM, so the time-series charts animate at 60 fps even when the user pinches into ten years of historic results. There's no JavaScript bridge bottleneck to design around. And because every chart pixel is owned by Flutter rather than the platform widget toolkit, the visual treatment we picked is identical across iOS and Android, which matters when half the user base is sharing screenshots with the other half on Reddit.
Code Generation Where It Helps
We leaned into Dart's code-generation ecosystem: Freezed for immutable models, Riverpod for type-safe dependency injection, JSON Serializable for the API layer. The build step pays for itself the first time a backend schema change surfaces as a compile-time error rather than a runtime null.
The AWS Pipeline: Textract, Bedrock, and Lambda
The hardest engineering problem in Health3 isn't the app. It's parsing the PDF the user uploads. Every lab uses a different template, fonts vary, and many reports are essentially scanned images of paper.
We built a serverless pipeline on AWS:
- Upload to S3 with a presigned URL scoped to the user's session, so the file never travels through our application server.
- AWS Textract runs document analysis, returning the structured blocks of text, tables, and key-value pairs the PDF actually contains. For machine-readable PDFs this gets us 90% of the way; for scans, Textract's OCR handles the pixel-to-text layer.
- AWS Bedrock (Claude on AWS) handles the semantic step: take Textract's raw blocks and map them to the canonical biomarker schema. Bedrock is the layer that knows "LDL Cholesterol", "LDL-C", "low-density lipoprotein cholesterol", and the Spanish "Colesterol LDL" all refer to the same biomarker.
- Lambda orchestrates the steps and writes the structured result back to Supabase.
The choice to put Bedrock between Textract and the database, rather than ship the user's raw PDF text to a model, means the prompt context is always small and structured. Cost per parse stays under a cent. Latency is under 30 seconds for a typical lab report, including the time the file spends in S3.
Why Bedrock, Not Direct LLM API Access
Bedrock keeps everything inside AWS. The user's lab data never leaves the VPC during processing, the IAM role on the Lambda controls who can invoke the model, and the audit trail for compliance reviews is generated automatically. For a health app subject to GDPR and best-effort HIPAA equivalents, this beat the operational cost of stitching together a third-party model provider with our own data-residency wrappers.
Supabase as the App Database
For everything that isn't the parse pipeline, Supabase is the backend. Row-level security policies enforce that a user can only ever read their own biomarker history, their own imported lab reports, and their own profile. The policies live in the database itself, so there's no "did the application layer remember to check?" failure mode, because the wrong query physically returns no rows.
Realtime subscriptions push new biomarker results into the running app the moment the Lambda finishes processing. The user uploads a PDF, sees a brief "processing" state, and the time-series chart updates without a manual refresh.
State Management: Riverpod for Calculation Correctness
We chose Riverpod over BLoC, Provider, and GetX for one reason: testability without BuildContext ceremony. Every health-data calculation in Health3 (unit conversion, reference-range bucketing, trend detection across imports) runs through Riverpod providers that can be unit-tested without instantiating a single widget. For a health app where a wrong number can be actively misleading, this was non-negotiable.
The reactive model also simplified the parse → display dataflow. When a new lab report finishes processing in the cloud, the realtime channel updates the relevant providers, the affected biomarker charts redraw automatically, and the Health Topic deep-dive views recompute their summaries, all through Riverpod's dependency graph, with no manual wiring.
Programmatic SEO at the Long Tail
Health3's traffic doesn't come from a single landing page. It comes from thousands of long-tail biomarker queries: what does ferritin 200 mean, mg/dL to mmol/L LDL, HbA1c 5.8 meaning. We treat the website as a programmatic-SEO surface in service of the app: every biomarker has a dedicated page, every common conversion has a dedicated page, every cluster of related biomarkers has a topic page.
The pages are generated from a single biomarker dataset that also powers the in-app library. One source, two surfaces. When we improve the dataset, both the website and the app benefit immediately.
The unit-conversion pages we shipped recently follow the same pattern: a few high-quality disambiguation pages (e.g. "100 mg/dL to mmol/L, which biomarker?") that resolve genuinely ambiguous searches and link to the dynamic converter for everything else. We deliberately avoided generating one static page per (value × biomarker) tuple because Google's near-duplicate filter punishes that pattern. Quality over volume.
24-Locale Hreflang Cluster
Health3 is internationalised end-to-end. Every tool page, every biomarker page, every conversion page ships in 24 locales with a full hreflang cluster pointing at the localised siblings. Google's hreflang validator passes on the production sitemap. International users searching in their own language reach a page that's actually localised, not a machine-translated stub.
The Result
Health3 grew to 700+ monthly active users across 27+ countries without paid acquisition. The SEO surface does the work, the parse pipeline removes the friction, and the app's chart quality keeps people logging in. The architecture has held up: zero infrastructure rewrites, zero migrations of historical data, and the same Flutter + Supabase + AWS stack we started with still serves every request.
If you're building a health-data app and you've been talking yourself out of the AI-augmented parse step because it sounds expensive, the Bedrock + Textract pipeline is the answer. The total monthly bill at our scale is two-digit dollars, not four-digit.
The Tech Stack
Flutter, Dart, iOS, Android, Supabase, PostgreSQL, AWS Lambda, AWS API Gateway, AWS Bedrock, AWS Textract, AWS CloudFormation, S3, CloudFront, Mixpanel, GitHub Actions.
Want a similar pipeline for your own product? Get in touch, we ship apps like this on a 30 to 60 day cadence.